This poster was presented at the Neural Information and Coding meeting,
March 16-19 1997, Snowbird, Utah.
INTERACTIVELY
EXPLORING A
NEURAL
CODE
BY
ACTIVE
LEARNING
Maneesh Sahani
Computation and Neural Systems Program
and Sloan Center for Theoretical Neuroscience
216-76 Caltech, Pasadena, CA 91125
neuronal response function
- Function that maps a space of stimuli to a scalar response of a
neuron or ensemble of neurons, for example
- firing rate in a given interval
- latency to the first spike or first burst
- the degree of synchrony in an ensemble
- Often called a ``tuning curve''. If it is separable in some
dimensions it is sometimes called a ``gain-field'' modulated curve.
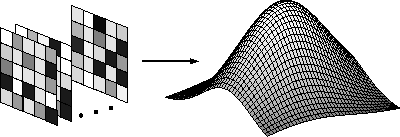
- The assumption that such a function exists is non-trivial. It
implies
- stationarity (or at least ergodicity in noise)
- instantaneous or finite-memory response
existing methods
- Regular sampling: Experimenter selects isolated points in
stimulus space arrayed in one or two dimensions.
- Response curve is taken to be a smooth function (often Gaussian or sigmoid) fit to samples.
- Very limited dimensionality. Strongly biased by choice of dimensions and sample points.
- White noise: Random exploration of stimulus space. Employed
in two types of study: Wiener/Volterra systems analysis and
spike-triggered statistics.
- Many stimuli elicit little or no response from cells (this is particularly true in the deeper layers of a system).
- Characterization of non-linear responses is difficult.
- Handles multiple temporal dimenensions cleanly. Systems analysis is difficult in multiple spatial dimensions.
- Non-linear search: Search in stimulus space for maximum response.
- Two example studies used Alopex (Tzanakou et al. 1979) and Simplex (Nelken et al. 1994) search.
- Inefficiencies due to step rejection.
- No averaging mechanism leads to poor behaviour in noise, particularly for alopex.
- Markov or Markov-like --- inefficient use of data.
active learning
- Use a generative model based on all of the data to direct sampling.
- At each time step:
- Find the curve that best describes the current data.
- Use the curve to choose where to sample next.
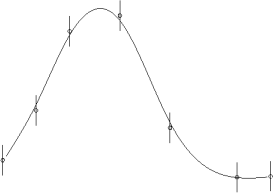
- This choice needs to balance two goals: fitting the curve well everywhere, and identifying its maximum precisely.
- terms and symbols:
target function f observations 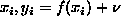
noise 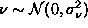
hypothesis class g(x;w) log posterior 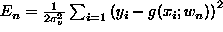
nth hypothesis 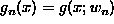
preliminaries
- Ideally, we would minimize a term such as
where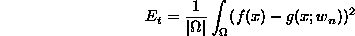
 is some region of interest.
is some region of interest.
- We do not know f, of course, so we approximate this integral by
where
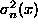 is the variance in the
estimator at x after the nth datum.
is the variance in the
estimator at x after the nth datum.
- Expanding the log posterior to second order about its maximum we
obtain the normal approximation to the posterior. Its covariance
matrix is given by the inverse of the Hessian at the maximum:
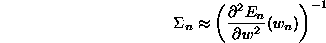
- The error bars on the estimator are then given by
where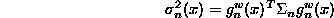
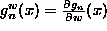 is the sensitivity of
the estimator at x to the weights.
is the sensitivity of
the estimator at x to the weights.
optimal experimental design
Technique from the statistics literature adapted for active learning by MacKay (1992) and Cohn (1994, 1995).
- Estimate based on
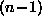 th curve and a candidate sample point
th curve and a candidate sample point
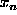 :
:
- Assume
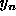 will be
distributed as predicted by the current model:
will be
distributed as predicted by the current model:
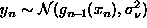
- Find expected value of under this distribution.
- Assume
- MacKay derives the expression
This approximation is quite brutal in general. However, it is exact for models that are linear in their parameters; but then does not depend on the data. For some non-parametric models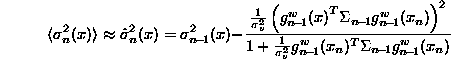
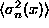 can be calculated directly
(Cohn et al. (1995)).
can be calculated directly
(Cohn et al. (1995)).
- Now choose to minimize

importance weighting
Modification of OED sampling (Sahani and Southworth 1997).
- The OED paradigm is uniformly concerned with variance along the entire curve. We wish to introduce a bias towards regions where the response is high.
- The target error function is now
where J(y) is an importance function.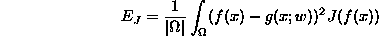
- J is not a prior on w and so
does not affect the likelihood. Thus
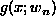 is the
same as before.
is the
same as before.
- We use
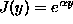 where the
parameter
where the
parameter 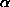 can be used to
control the degree of emphasis on high-valued regions.
can be used to
control the degree of emphasis on high-valued regions.
- As before, we approximate
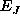 by
by
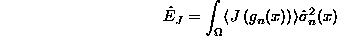
- We cannot replace
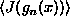 by
by
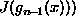 because this will
improperly ignore regions of low estimate but high variance,
that might be important.
because this will
improperly ignore regions of low estimate but high variance,
that might be important.
- If we assume that
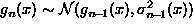 and use
and use
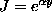 , the expectation is
, the expectation is
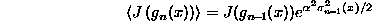
- Now we choose to minimize
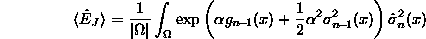
learning model
- We have found that the procedure is extremely sensitive to the choice of hypothesis class.
- Strongly parameterized models (such as Gaussian curves), with
localized
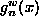 , do not work well if
the target function is not drawn from the same family, or if initial
estimates are very far from the truth. Even in unweighted active
learning, samples are directed only towards regions of high
, do not work well if
the target function is not drawn from the same family, or if initial
estimates are very far from the truth. Even in unweighted active
learning, samples are directed only towards regions of high
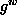 .
.
- Nonparametric, or weakly parametric families (in the sense of
fairly even ) are more successful.
- LOESS and kernel-weighted regression are solved exactly in Cohn et al. (1995), but involve strong assumptions that make variance estimates misleading.
- Polynomial and spline models have proven successful. These are
linear in parameters, and so are uninteresting in conventional active
learning. However, they are useful in importance-weighted sampling.
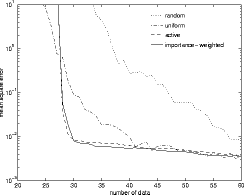
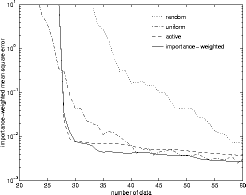
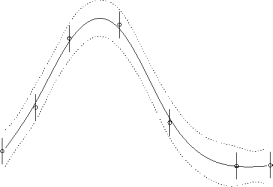
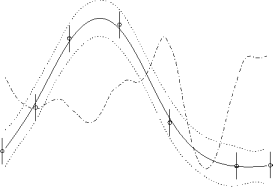
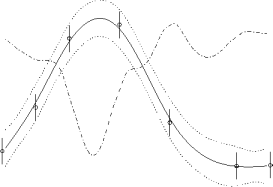
- The performance of various sampling regimes is a polynomial regression
task is shown above. The left graph shows uniform error
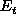 while
the right shows importance weighted error
.
while
the right shows importance weighted error
.
references
- D. A. Cohn, (1994) ``Neural Network Exploration Using Optimal Experimental Design.'' In J. Cowan, et al., eds., Advances in Neural Information Processing Systems 6, Morgan Kaufmann, San Francisco.
- D. A. Cohn, Z. Ghahramani, and M. I. Jordan, (1995) ``Active Learning with Statistical Models.'' In G. Tesaruo, D. Touretzky and T. Leen, eds., Advances in Neural Information Processing Systems 7, MIT Press, Cambridge, MA.
- D. MacKay, (1992) ``Information-based objective functions for active data selection.'' Neural Comp. 4(4):590-604.
- I. Nelken, Y. Prut, E. Vaadia and M. Abeles, (1994) ``In Search of the Best Stimulus - an Optimization Procedure for Finding Efficient Stimuli in the Cat Auditory-Cortex.'' Hearing Research 72(1-2):237-253.
- M. Sahani and R. Southworth (1997) ``Active Learning for an Ulterior Motive.'' Unpublished.
- E. Tzanakou, R. Michalak, and E. Harth, (1979) ``The Alopex Process: Visual Receptive Fields by Response Feedback.'' Biol. Cybernetics, 35:161-174.
acknowledgements
The work on importance-weighted sampling was done by Robert
Southworth and myself as a project for a class on Learning Systems
taught by Yaser Abu-Mostafa. Support for this work was provided by
both the Sloan Center for Theoretical Neuroscience and the NSF Center
for Neuromorphic Engineering.