CHIA (CAGLIARI), ITALY, SEPTEMBER 23-27, 1996.
EXTRACELLULAR RECORDING FROM MULTIPLE NEIGHBORING CELLS IN PRIMATE CORTEX
M. Sahani, J. S. Pezaris, R. A. Andersen
Division of Biology
Computation and Neural Systems
Caltech, Pasadena, CA 91125, USA
panel 1: introduction
In this poster we describe our efforts to record and interpret signals from neighboring cells in the posterior parietal cortex of the macaque. We focus primarily on the technical issues raised in this project, and include data from one recording site as an illustration. The collection and analysis of data is ongoing.
unravelling dynamical microcircuits
- Computation within a single cortical area is likely to be a
dynamic process, involving local recurrent circuitry.
- Anatomical studies suggest that cells within a single column, or
even closer, have the connectivity necessary to form recurrent
microcircuits.
- To understand the computations carried out by these
microcircuits, and the functional relevance of the connections within
them, we need to be able to record simultaneously in a behaving animal
from the cells that comprise them.
concerted signaling
- Nearby cells in cortex tend to be both anatomically connected and
functionally related.
- Thus both the opportunity and the motive for concerted
signaling by neighboring neurons is present.
panel 2: tetrodes
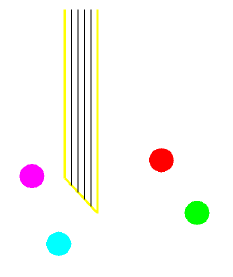
- Tetrodes are extracellular micro-electrodes made from a bundle
of four insulated wires, twisted and glued together.
- The tip is cut and each exposed conductor plated for about 10
microamp-seconds in AuCl4.
- Action potentials from each cell close to the tip generate
detectable waveforms on each wire. As in quadraphonic sound, the
four-channel signature of each cell is determined both by the source
field generated by the spike as well as the cell's spatial
relationship to the electrode.
- In the diagram, the magenta and cyan cells are each close to one
wire tip, while the red and green ones are distant.
- We have been able to record and recognize up to 7 cells within an estimated 100 micron diameter volume.
panel 3: photomicrograph
panel 4: spike recognition
two stages
- Identify the family of spike shapes associated with each
detectable cell. This stage corresponds to the familiar ``spike
clustering'' operation.
- Identify the times when action potentials from each cell occurred. In general this is performed by a filter-like algorithm.
filtering is important
- Event detection schemes to provide candidate spike shapes for
clustering are dependent on the shapes of the events in the data. In
the extreme case of a simple threshold, clusters that lie close to the
threshold will be incompletely detected. More sophisticated general
template techniques can be improved by knowing the precise templates
to search for.
- Overlapped spikes generally defeat clustering algorithms. We
are particularly interested in spikes that arrive within 2ms of each
other, where the probability of overlap is large. Filtering
techniques, particularly if linear, can resolve such cases accurately.
- Clustering algorithms are generally worse than O(n), and require multiple iterations over the entire data set. Greater efficiency is possible by clustering a small group of events and converting to filters to detect subsequent spikes.
panel 5: signal processing
analog signal
- The signals are amplified with a two-stage gain of 80-100
dB (custom).
- They are then low-pass filtered (9-pole analog Bessel) at 6.4
kHz to prevent aliasing (Tucker Davis Technologies, Gainsville, Florida).
- They are digitized at 12.8 kHz on each channel by a 16 bit
instrumentation A/D (TDT).
- Finally, they are high-pass filtered using a 32-tap digital Hamming windowed FIR filter with the 3dB point at 640Hz.
event detection
- Events are detected by threshold crossing, with the threshold
set to 4 to 6 times the RMS
of the filtered signal. See the panel above for comments on this
process.
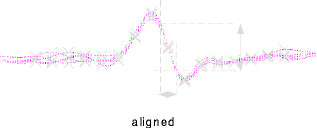
- Event waveforms are reconstructed with Fourier techniques, and the events are resampled to align the sampling frame with the reconstructed peak. See below for a discussion of the significance of this.
panel 6: clustering - subspace
choosing the subspace
- Events are stored as 64-sample vectors (16 samples per channel)
with the reconstructed peak at sample number 8.
- Clustering simply on peak height (that is, sample number 8)
seems to be remarkably effective. This exploits the quadraphonic
amplitude effect of the tetrode.
- Non-linear transformations (such as peak width) might, in
principle, be useful. We have not seen remarkable improvements,
however.
- Linear transformations of the vector (such as PCA) should only be useful for dimensionality reduction. If a clustering algorithm can run in the higher dimensional space it should perform as well as on the transformed space. In particular, we have had little success with PCA since we often see noise or burst variation dominating inter-cluster variation, as in the example below.
panel 7: clustering - noise
choosing the noise model
- Electrical noise and noise due to the superposition of
sub-threshold neural events (``background noise'') may be taken to be
gaussian.
- Noise due to sample frame shifts is uniform and unequal at
points along the waveform (it is proportional to the local
derivative). At points near the waveform peak at our sample rate it
can approach one quarter the magnitude of the signal. At twice our
sampling rate the SNR is still 8. This noise source may dominate
gaussian sources and must be removed prior to gaussian model
fitting.

- Intrinsic spike variability is also non-gaussian and
anisotropic. This is not easily removed (although a predictive burst
model involving a mean waveform varying with time since the last spike
could be combined with a gaussian noise assumption). We follow Fee
et al (1996) in fitting more clusters that expected and then ``merging'' clusters so as to describe a single cell by multiple centers. However we use a mixture of gaussians with general (i.e. non-isotropic) covariance matrices for the initial fitting, and thus frequently capture bursting variability in the first stage. We are therefore relatively successful with far fewer initial models than used by Feeet al .
panel 8: em mathematics
- We are given observations di that are presumed to have arisen
from the mixture
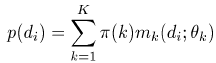
Here mk represents the probability density function, thetak the parameters, and pi(k) the mixture probability, of the kth model. We would like to ``fit'' this mixture model to the data, that is we want thetak and pi(k) for all k, such that p(di) is maximized.
- If we knew which model the ith data point came from, that is,
if we had the labels {ki}, this problem would be easy (at
least for gaussian mixtures). We could simply fit each model
mk(di;thetak) to
maximize the probability of those di labeled to come
from that model.
- The EM (Estimation Maximization) algorithm iterates the following two
steps:
Estimate a probability distribution for the missing data. In the mixture case these are the labels {ki}. We make the distribution for ki proportional to the likelihood of the data point di under the kith model from the previous iteration, i.e.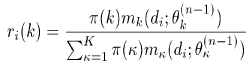
-
Maximize the likelihood of the observed and estimated data. In this case we fit the models to the labeled data weighted by the probabilities ri(k):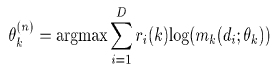
panel 9: em results
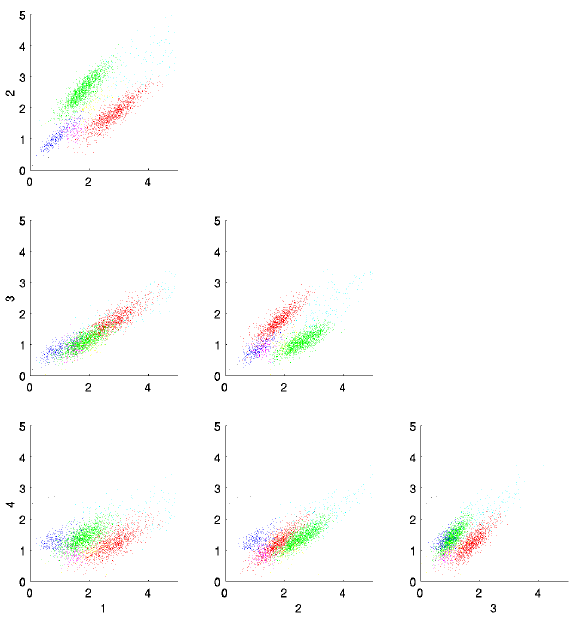
- These plots show peak heights on the 4 channels (in volts at
digitization) of about 1/10 of the events recorded at one site. The
clusters have been identified by EM fitting a mixture of gaussians with
unconstrained covariance matrices to the 4-element peak vector. Assignment
to gaussians is done by greatest likelihood.
- Pay special attention to the magenta cluster. It would be quite difficult to identify this group by hand.
panel 10: filtering
optimal linear filtering
- Roberts and Hartline (1975), and Gozani and Miller (1994) have
suggested the following straightforward procedure. The center of each
cluster mk(t) and the typical noise waveform
eta(t) are identified, and an optimal matched filter (method
due to Wiener) is generated for each template
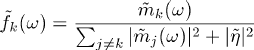
Where tilde indicates Fourier transformation to the frequency domain. A frequency dependent prefactor may also be introduced.
- The filter is optimal in the sense that the response to the
distractors (mj(t) and eta(t)) is
minimized under the constraint that the response to
mk(t) is unity. Informally, the filter modifies
the simplest matched filter, which is just the spike template itself, by
deemphasizing frequency channels where the template shares power with the
distractors.
- If such filters can be constructed, overlap resolution will be
automatic. The response of each filter to the overlap will be the
sum of the responses to the spikes in the overlap, which will be 1
if and only if the corresponding template is present. A simple
threshold on the output of the filter should therefore suffice.
- In practice spike waveforms are sufficiently similar that orthogonalization of the filters is not possible.
panel 11: more filtering
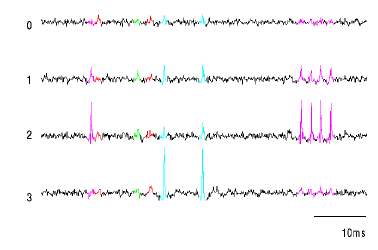
- The figure below shows the output of filters based on the three
prominent clusters in the cluster diagram above.
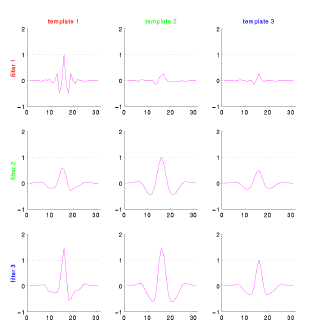
- It is clear that while filter for the red cell is well orthogonalized to the distractor templates, the other two filters are quite poor.
nonlinear filtering
- While more work is necessary to resolve overlaps, nonlinear filtering techniques may be useful. Recently Chandra and Optican (1996) have implemented a two-layer network architecture to sort signals from a single electrode. We continue to examine this and other possibilities.
panel 12: example data
The data used to demonstrate the sorting process above was taken from a site at a depth of about 3mm in the posterior parietal cortex of a behaving macaque. Closer examination of these data proves to be instructive.
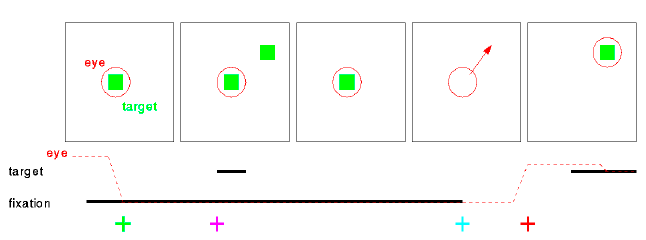
task
- The monkey is performing the delayed saccade task. He fixates a point of light on a dark screen while a peripheral target light is flashed. He must remember the location of the target, and when the fixation point is extinguished make a direct saccade to it. Once his eye has stopped in the correct area the target is re-illuminated to provide feedback (which usually results in another, corrective, saccade).
cells
- We shall examine the three relatively frequently firing cells, colored red, green and blue in the cluster diagrams.
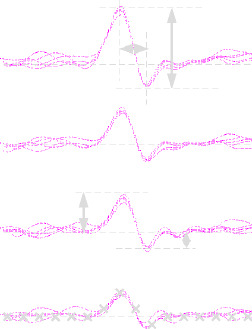
panel 13: cell responses
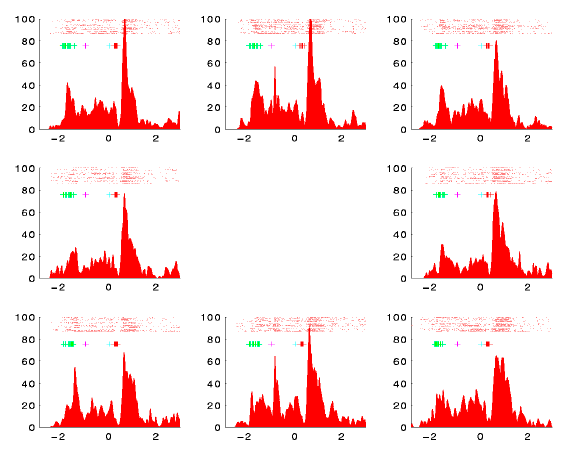
- These diagrams show PST histograms and rasters for the cells
detected at our example site. The eight histograms are aligned on the
fixation offset (cue to saccade). Each subpanel collects trials for a
target in a single peripheral location. The direction is indicated by
the position of the subpanel relative to the center of the group. The
locations were 15 degrees from fixation.
- The crosses indicate the times of behavioral events during the
trial as follows: green, fixation acquisition; magenta, target
presentation; cyan, fixation offset; red, target acquisition.
- Note that the red cell responds strongly after both saccades (coming on to fixation and moving to the target). It also exhibits a sharp sensory response to targets flashed directly above or below fixation.
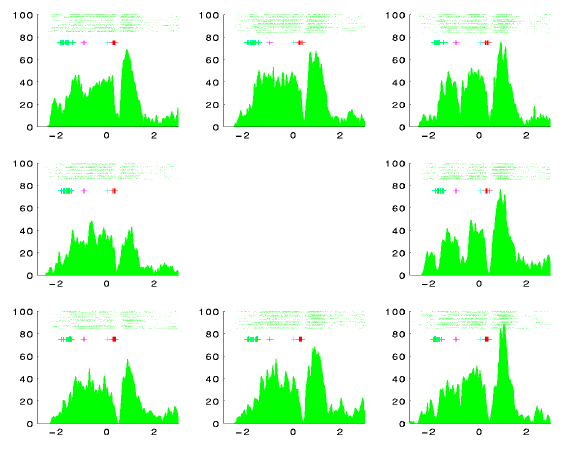
- The green and blue cells fire throughout active fixation periods. They are pre-saccadically suppressed and rebound after the saccade. Presumably they are involved in maintenance of active fixation, or have foveal sensory receptive fields.
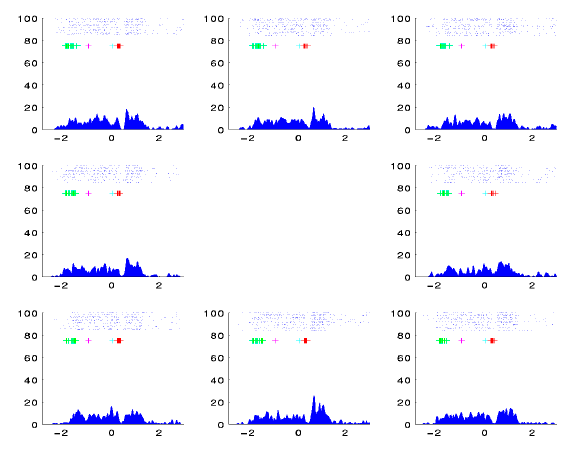
panel 14: correlations
long time scale
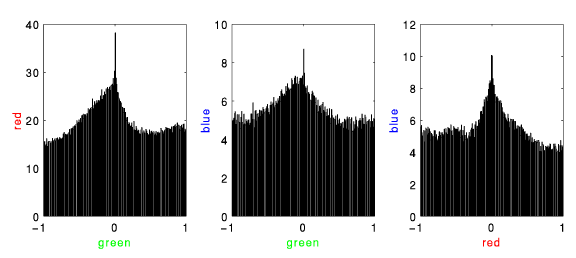
- The green cell seems to trail both red and blue. This is somewhat consistent with the PSTHs and is probably stimulus induced (these correlograms are not corrected for stimulus effects).
short time scale
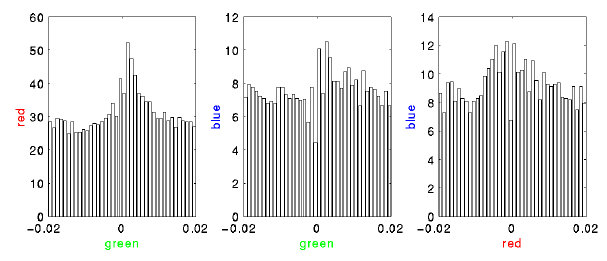
- Here the green cell leads the other two with a time delay consistent with monosynaptic transmission. We believe this to reflect the underlying connectivity. Note that because the analysis used to create these correlations did not fully handle overlapped events, the actual counts in the zero-delay bins are likely higher than reported.