Evaluating and Training
Implicit Generative Models
with Two-Sample Tests
Dougal J. Sutherland
Gatsby unit, University College London
Implicit Generative Models workshop, ICML 2017
Implicit generative models
- Given some samples from a distribution on
- Goal: generate more samples from
- Don't have an explicit likelihood model

Evaluating implicit generative models
- Can't evaluate standard test-set likelihood
- Early GAN papers: estimate this with KDE
- KDE doesn't work in high , theoretically or empirically
- Models with high likelihoods can have terrible samples; those with good samples can have awful likelihoods [Theis+ ICLR-16]

Max-likelihood objective vs WGAN objective [Danihelka+ 2017]
Other evaluation methods
- Birthday paradox test [Arora/Zhang 2017]
- Needs a human
- Only measures diversity
- Inception score [Salimans+ NIPS-16]
- Domain-specific
- Only measures label-level diversity
- …
- Look at a bunch of pictures and see if they're pretty or not
- Easy to find bad samples
- Hard to see if modes missing, wrong probabilities
- Hard to compare models
Two-sample tests
- Given samples from two unknown distributions
- Question: is ?
- Hypothesis testing approach:
Applications of two-sample testing
- Does my generative model match ?
- Do smokers/non-smokers have different cancer rates?
- Do these neurons fire differently when the subject is reading?
- Do these columns from different databases mean the same?
- Independence: is ?
General scheme for two-sample tests
- Choose some notion of distance
- Ideally, iff
- Estimate the distribution distance from data:
- Say when
- Want (at least approximately) test of level :
- Test power is probability of true rejection: when ,
Mean difference


Variance difference



Higher-order differences


Need higher-order features still
Could keep stacking up moments, but get hard to estimate
Instead: use features , for an RKHS
Refresher: Reproducing Kernel Hilbert Spaces
- Using mean embedding
- corresponds to kernel
- For any positive semidefinite , a matching and exist
- e.g.
- Reproducing property: ,
Maximum Mean Discrepancy
Estimating MMD
 |  |  |  |  |  | |
|---|---|---|---|---|---|---|
| 1.0 | 0.6 | 0.5 | 0.2 | 0.4 | 0.2 |
| 0.6 | 1.0 | 0.7 | 0.4 | 0.1 | 0.1 |
| 0.5 | 0.7 | 1.0 | 0.3 | 0.1 | 0.2 |
| 0.2 | 0.4 | 0.3 | 1.0 | 0.7 | 0.8 |
| 0.4 | 0.1 | 0.1 | 0.7 | 1.0 | 0.6 |
| 0.2 | 0.1 | 0.2 | 0.8 | 0.6 | 1.0 |
MMD two-sample test
- Distance :
- Need to choose a kernel
- For characteristic , iff
- Estimate the distance from data:
- Choose a rejection threshold
- Use permutation testing to set
Functional form of MMD
Form called integral probability metric
Maximizing function called witness function (or critic)
Witness function

Witness function

Witness function

Witness function

Witness function

Witness function

The kernel matters!
The kernel matters!

The kernel matters!

Choosing a kernel

Choosing a kernel

Choosing a kernel

But how do we actually choose the kernel?
We want the most powerful test

Optimizing test power
- Turns out a good proxy for asymptotic power is:
- Can estimate this in quadratic time
- …in an autodiff-friendly way
Generative model criticism
Take a really good GAN on MNIST: [Salimans+ NIPS-16]



Samples are distinguishable
ARD kernel on pixels:
p-values almost exactly zero

Investigating indicative points
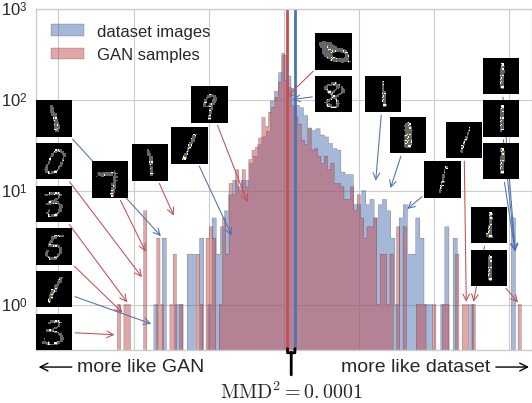
Testing to generative modeling
- Natural idea: train a generator to minimize power of test
- Consistent test, powerful generator class, infinite samples:
- Tradeoffs for unrealizable case depend on test
Integral probability metrics (IPMs)
Get different distances for different choices of :
- with : MMD
- with : total variation
- that are 1-Lipschitz: Wasserstein
- …
Classifier two sample tests (C2STs)
- Let be set of functions :
- Estimator :
- Asymptotic power is monotonic function of

Generative model based on C2STs
- Train to minimize C2ST power = accuracy of classifier
- Accuracy hard to optimize, so use logistic surrogate
- Envelope theorem:
- Waste to retrain classifier each time: keep one discriminator
- …and now we have a GAN
Generative Moment Matching Networks
[Li+ ICML-15], [Dziugate+ UAI-15]
- Minimize
- Samples are okay on MNIST
- -GMMN using test power instead: basically the same
- Hard to choose a good kernel
Optimizing the kernel
- Alternate updating the generator and updating the test kernel
- As-is, runs into serious stability problems. Various fixes:
- MMD GAN [Li+ 2017]
- RBF kernel, WGAN weight clipping [Arjovsky+ ICML-17]
- Cramér GAN [Bellemare+ 2017]
- Distance kernel, WGAN-GP gradient penalty [Gulrajani+ 2017]
- Distributional Adversarial Networks [Li+ 2017]
- dfGMMN [Liu 2017]
- TextGAN [Zhang+ ICML-17]
Evaluating implicit generative models
- One useful way is via two-sample-testing framework
- MMD is a nice two-sample test, when you learn the kernel
- Can help diagnose problems
- More things to try for use on practical image problems
Training implicit generative models
- Can define models based on power of two-sample tests
- Might help with stability of training, etc