2018
Andrea Banino, Caswell Barry, Benigno Uria, Charles Blundell, Timothy Lillicrap, Piotr Mirowski, Alexander Pritzel, Thomas Degris, Joseph Modayil, Greg Wayne, Hubert Soyer, Fabio Viola, Brian Zhang, Ross Goroshin, Neil Rabinowitz, Razvan Pascanu, Charlie Beattie, Stig Petersen, Amir Sadik, Stephen Gaffney, Helen King, Koray Kavukcuoglu, Demis Hassabis, Raia Hadsell, Dharshan Kumaran
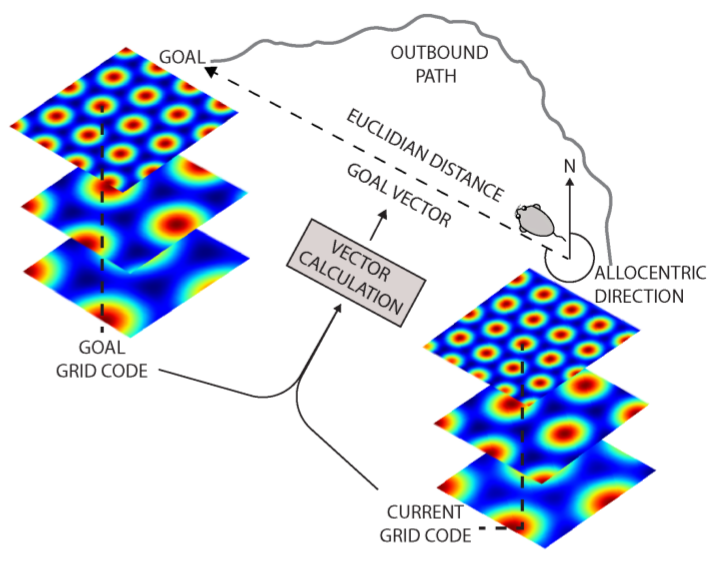
Deep neural networks have achieved impressive successes in fields ranging from object recognition to complex games such as Go. Navigation, however, remains a substantial challenge for artificial agents, with deep neural networks trained by reinforcement learning failing to rival the proficiency of mammalian spatial behaviour, which is underpinned by grid cells in the entorhinal cortex. Grid cells are thought to provide a multi-scale periodic representation that functions as a metric for coding space and is critical for integrating self-motion (path integration) and planning direct trajectories to goals (vector-based navigation). Here we set out to leverage the computational functions of grid cells to develop a deep reinforcement learning agent with mammal-like navigational abilities. We first trained a recurrent network to perform path integration, leading to the emergence of representations resembling grid cells, as well as other entorhinal cell types. We then showed that this representation provided an effective basis for an agent to locate goals in challenging, unfamiliar, and changeable environments-optimizing the primary objective of navigation through deep reinforcement learning. The performance of agents endowed with grid-like representations surpassed that of an expert human and comparison agents, with the metric quantities necessary for vector-based navigation derived from grid-like units within the network. Furthermore, grid-like representations enabled agents to conduct shortcut behaviours reminiscent of those performed by mammals. Our findings show that emergent grid-like representations furnish agents with a Euclidean spatial metric and associated vector operations, providing a foundation for proficient navigation. As such, our results support neuroscientific theories that see grid cells as critical for vector-based navigation, demonstrating that the latter can be combined with path-based strategies to support navigation in challenging environments.
Pablo Sprechmann, Siddhant Jayakumar, Jack Rae, Alexander Pritzel, Adrià Puigdomènech, Benigno Uria, Oriol Vinyals, Demis Hassabis, Razvan Pascanu, Charles Blundell
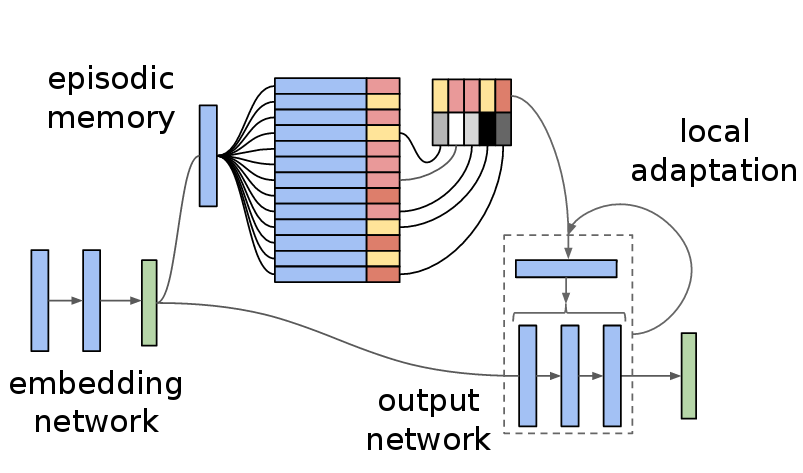
Deep neural networks have excelled on a wide range of problems, from vision to language and game playing. Neural networks very gradually incorporate information into weights as they process data, requiring very low learning rates. If the training distribution shifts, the network is slow to adapt, and when it does adapt, it typically performs badly on the training distribution before the shift. Our method, Memory-based Parameter Adaptation, stores examples in memory and then uses a context-based lookup to directly modify the weights of a neural network. Much higher learning rates can be used for this local adaptation, reneging the need for many iterations over similar data before good predictions can be made. As our method is memory-based, it alleviates several shortcomings of neural networks, such as catastrophic forgetting, fast, stable acquisition of new knowledge, learning with an imbalanced class labels, and fast learning during evaluation. We demonstrate this on a range of supervised tasks: large-scale image classification and language modelling.
Meire Fortunato, Mohammad Gheshlaghi Azar, Bilal Piot, Jacob Menick, Ian Osband, Alex Graves, Vlad Mnih, Remi Munos, Demis Hassabis, Olivier Pietquin, Charles Blundell, Shane Legg
We introduce NoisyNet, a deep reinforcement learning agent with parametric noise added to its weights, and show that the induced stochasticity of the agent's policy can be used to aid efficient exploration. The parameters of the noise are learned with gradient descent along with the remaining network weights. NoisyNet is straightforward to implement and adds little computational overhead. We find that replacing the conventional exploration heuristics for A3C, DQN and dueling agents (entropy reward and $\epsilon$-greedy respectively) with NoisyNet yields substantially higher scores for a wide range of Atari games, in some cases advancing the agent from sub to super-human performance.
2017
Balaji Lakshminarayanan, Alexander Pritzel, Charles Blundell
Deep neural networks are powerful black box predictors that have recently achieved impressive performance on a wide spectrum of tasks. Quantifying predictive uncertainty in neural networks is a challenging and yet unsolved problem. Bayesian neural networks, which learn a distribution over weights, are currently the state-of-the-art for estimating predictive uncertainty; however these require significant modifications to the training procedure and are computationally expensive compared to standard (non-Bayesian) neural neural networks. We propose an alternative to Bayesian neural networks, that is simple to implement, readily parallelisable and yields high quality predictive uncertainty estimates. Through a series of experiments on classification and regression benchmarks, we demonstrate that our method produces well-calibrated uncertainty estimates which are as good or better than approximate Bayesian neural networks. To assess robustness to dataset shift, we evaluate the predictive uncertainty on test examples from known and unknown distributions, and show that our method is able to express higher uncertainty on unseen data. We demonstrate the scalability of our method by evaluating predictive uncertainty estimates on ImageNet.
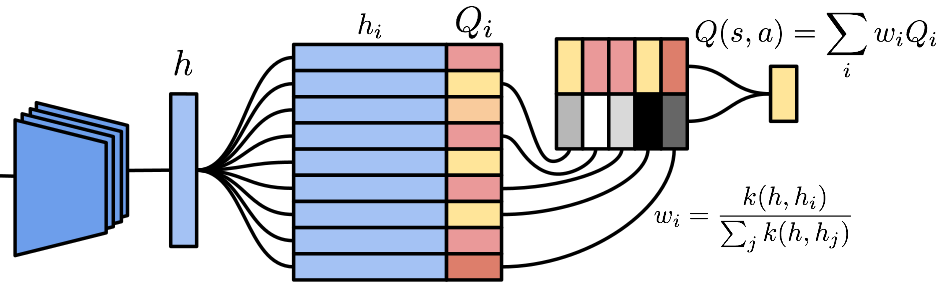
Alexander Pritzel, Benigno Uria, Sriram Srinivasan, Adrià Puigdomènech, Oriol Vinyals, Demis Hassabis, Daan Wierstra, Charles Blundell
Deep reinforcement learning methods attain super-human performance in a wide range of environments. Such methods are grossly inefficient, often taking orders of magnitudes more data than humans to achieve reasonable performance. We propose Neural Episodic Control: a deep reinforcement learning agent that is able to rapidly assimilate new experiences and act upon them. Our agent uses a semi-tabular representation of the value function: a buffer of past experience containing slowly changing state representations and rapidly updated estimates of the value function. We show across a wide range of environments that our agent learns significantly faster than other state-of-the-art, general purpose deep reinforcement learning agents.
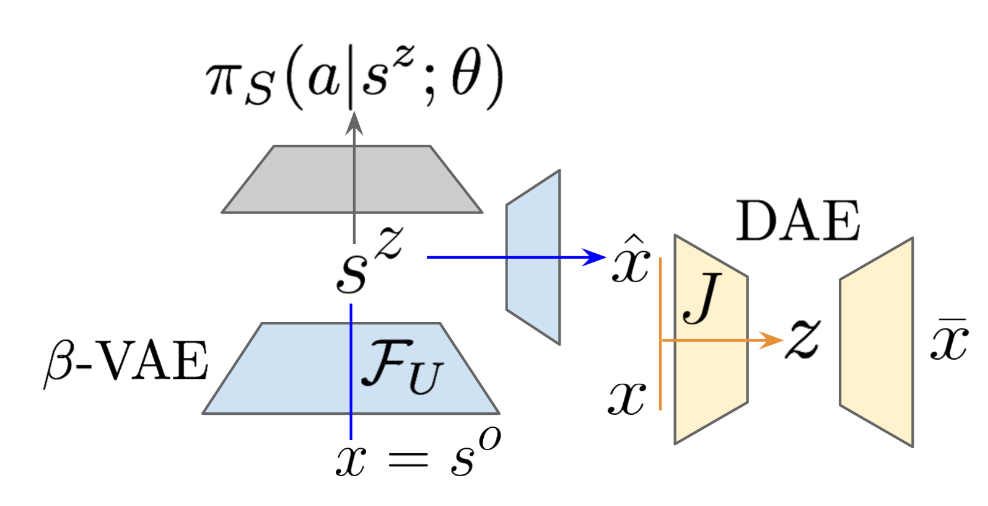
Irina Higgins, Arka Pal, Andrei A. Rusu, Loic Matthey, Christopher P Burgess, Alexander Pritzel, Matt Botvinick, Charles Blundell, Alexander Lerchner
Domain adaptation is an important open problem in deep reinforcement learning (RL). In many scenarios of interest data is hard to obtain, so agents may learn a source policy in a setting where data is readily available, with the hope that it generalises well to the target domain. We propose a new multi-stage RL agent, DARLA (DisentAngled Representation Learning Agent), which learns to see before learning to act. DARLA's vision is based on learning a disentangled representation of the observed environment. Once DARLA can see, it is able to acquire source policies that are robust to many domain shifts - even with no access to the target domain. DARLA significantly outperforms conventional baselines in zero-shot domain adaptation scenarios, an effect that holds across a variety of RL environments (Jaco arm, DeepMind Lab) and base RL algorithms (DQN, A3C and EC).
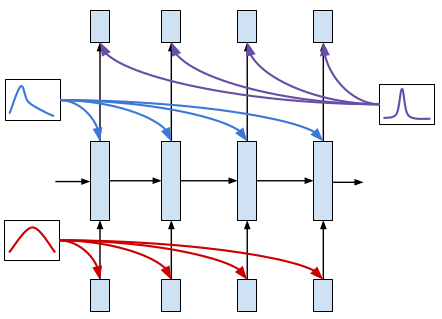
Meire Fortunato, Charles Blundell, Oriol Vinyals
In this work we explore a straightforward variational Bayes scheme for Recurrent Neural Networks. Firstly, we show that a simple adaptation of truncated backpropagation through time can yield good quality uncertainty estimates and superior regularisation at only a small extra computational cost during training. Secondly, we demonstrate how a novel kind of posterior approximation yields further improvements to the performance of Bayesian RNNs. We incorporate local gradient information into the approximate posterior to sharpen it around the current batch statistics. This technique is not exclusive to recurrent neural networks and can be applied more widely to train Bayesian neural networks. We also empirically demonstrate how Bayesian RNNs are superior to traditional RNNs on a language modelling benchmark and an image captioning task, as well as showing how each of these methods improve our model over a variety of other schemes for training them. We also introduce a new benchmark for studying uncertainty for language models so future methods can be easily compared.
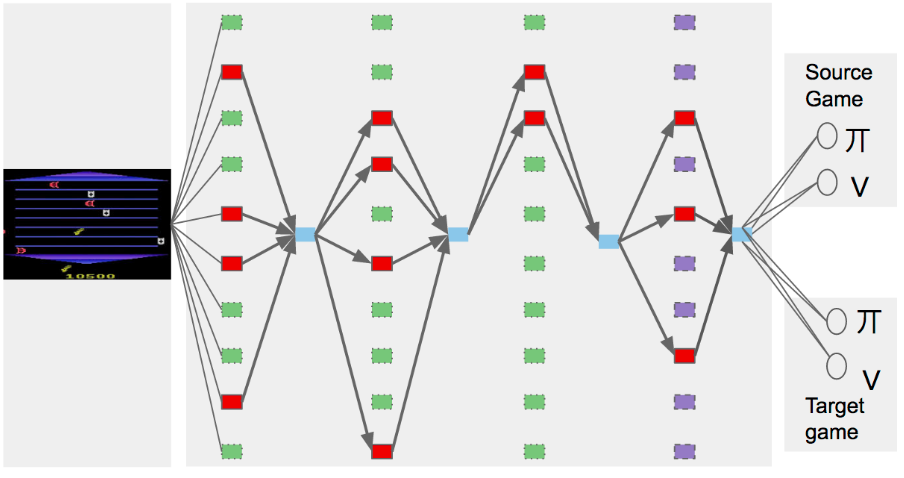
Chrisantha Fernando, Dylan Banarse, Charles Blundell, Yori Zwols, David Ha, Andrei A. Rusu, Alexander Pritzel, Daan Wierstra
For artificial general intelligence (AGI) it would be efficient if multiple users trained the same giant neural network, permitting parameter reuse, without catastrophic forgetting. PathNet is a first step in this direction. It is a neural network algorithm that uses agents embedded in the neural network whose task is to discover which parts of the network to re-use for new tasks. Agents are pathways (views) through the network which determine the subset of parameters that are used and updated by the forwards and backwards passes of the backpropogation algorithm. During learning, a tournament selection genetic algorithm is used to select pathways through the neural network for replication and mutation. Pathway fitness is the performance of that pathway measured according to a cost function. We demonstrate successful transfer learning; fixing the parameters along a path learned on task A and re-evolving a new population of paths for task B, allows task B to be learned faster than it could be learned from scratch or after fine-tuning. Paths evolved on task B re-use parts of the optimal path evolved on task A. Positive transfer was demonstrated for binary MNIST, CIFAR, and SVHN supervised learning classification tasks, and a set of Atari and Labyrinth reinforcement learning tasks, suggesting PathNets have general applicability for neural network training. Finally, PathNet also significantly improves the robustness to hyperparameter choices of a parallel asynchronous reinforcement learning algorithm (A3C).
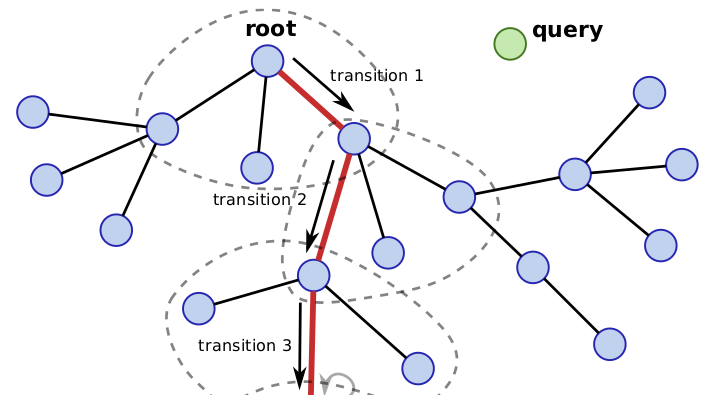
Daniel Zoran, Balaji Lakshminarayanan, Charles Blundell
Nearest neighbor (kNN) methods have been gaining popularity in recent years in light of advances in hardware and efficiency of algorithms. There is a plethora of methods to choose from today, each with their own advantages and disadvantages. One requirement shared between all kNN based methods is the need for a good representation and distance measure between samples. We introduce a new method called differentiable boundary tree which allows for learning deep kNN representations. We build on the recently proposed boundary tree algorithm which allows for efficient nearest neighbor classification, regression and retrieval. By modelling traversals in the tree as stochastic events, we are able to form a differentiable cost function which is associated with the tree's predictions. Using a deep neural network to transform the data and back-propagating through the tree allows us to learn good representations for kNN methods. We demonstrate that our method is able to learn suitable representations allowing for very efficient trees with a clearly interpretable structure.
2016
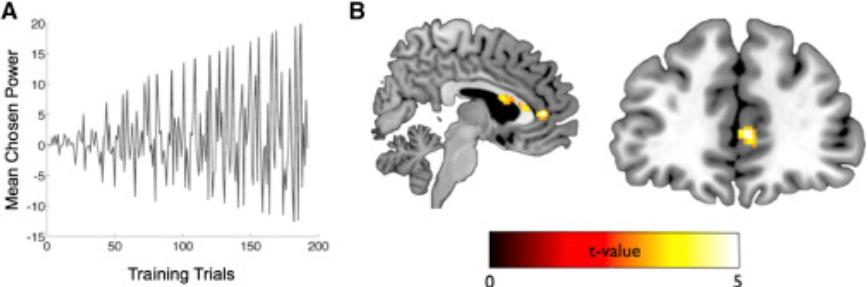
Dharshan Kumaran, Andrea Banino, Charles Blundell, Demis Hassabis, Peter Dayan
Knowledge about social hierarchies organizes human behavior, yet we understand little about the underlying computations. Here we show that a Bayesian inference scheme, which tracks the power of individuals, better captures behavioral and neural data compared with a reinforcement learning model inspired by rating systems used in games such as chess. We provide evidence that the medial prefrontal cortex (MPFC) selectively mediates the updating of knowledge about one's own hierarchy, as opposed to that of another individual, a process that underpinned successful performance and involved functional interactions with the amygdala and hippocampus. In contrast, we observed domain-general coding of rank in the amygdala and hippocampus, even when the task did not require it. Our findings reveal the computations underlying a core aspect of social cognition and provide new evidence that self-relevant information may indeed be afforded a unique representational status in the brain.
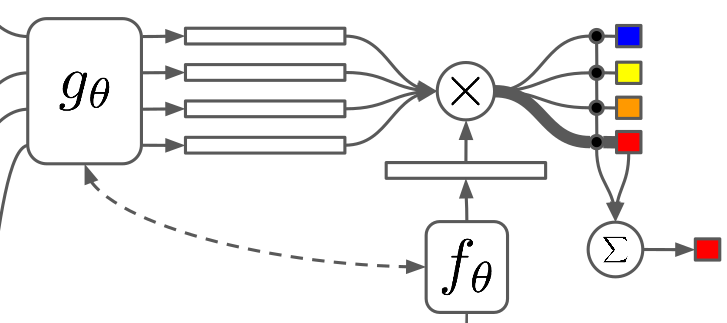
Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Koray Kavukcuoglu, Daan Wierstra
Learning from a few examples remains a key challenge in machine learning. Despite recent advances in important domains such as vision and language, the standard supervised deep learning paradigm does not offer a satisfactory solution for learning new concepts rapidly from little data. In this work, we employ ideas from metric learning based on deep neural features and from recent advances that augment neural networks with external memories. Our framework learns a network that maps a small labelled support set and an unlabelled example to its label, obviating the need for fine-tuning to adapt to new class types. We then define one-shot learning problems on vision (using Omniglot, ImageNet) and language tasks. Our algorithm improves one-shot accuracy on ImageNet from 87.6% to 93.2% and from 88.0% to 93.8% on Omniglot compared to competing approaches. We also demonstrate the usefulness of the same model on language modeling by introducing a one-shot task on the Penn Treebank.
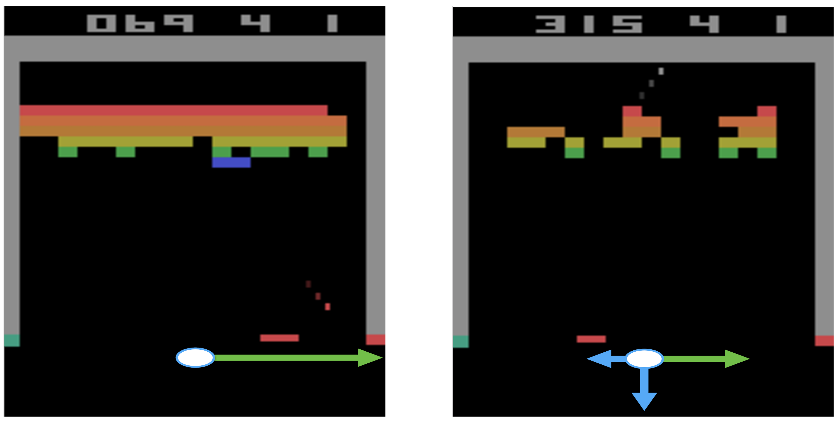
Ian Osband, Charles Blundell, Alexander Pritzel, Benjamin Van Roy
Efficient exploration in complex environments remains a major challenge for reinforcement learning. We propose bootstrapped DQN, a simple algorithm that explores in a computationally and statistically efficient manner through use of randomized value functions. Unlike dithering strategies such as epsilon-greedy exploration, bootstrapped DQN carries out temporally-extended (or deep) exploration; this can lead to exponentially faster learning. We demonstrate these benefits in complex stochastic MDPs and in the large-scale Arcade Learning Environment. Bootstrapped DQN substantially improves learning times and performance across most Atari games.
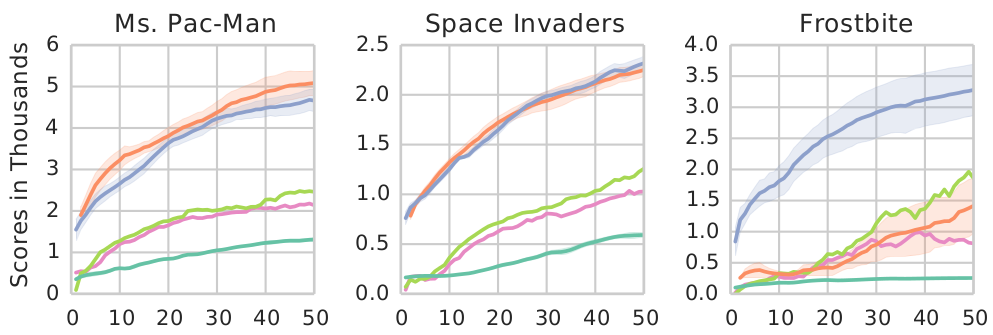
Charles Blundell, Benigno Uria, Alexander Pritzel, Yazhe Li, Avrham Ruderman, Joel Z Leibo, Jack Rae, Daan Wierstra, Demis Hassabis
State of the art deep reinforcement learning algorithms take many millions of interactions to attain human-level performance. Humans, on the other hand, can very quickly exploit highly rewarding nuances of an environment upon first discovery. In the brain, such rapid learning is thought to depend on the hippocampus and its capacity for episodic memory. Here we investigate whether a simple model of hippocampal episodic control can learn to solve difficult sequential decision-making tasks. We demonstrate that it not only attains a highly rewarding strategy significantly faster than state-of-the-art deep reinforcement learning algorithms, but also achieves a higher overall reward on some of the more challenging domains.
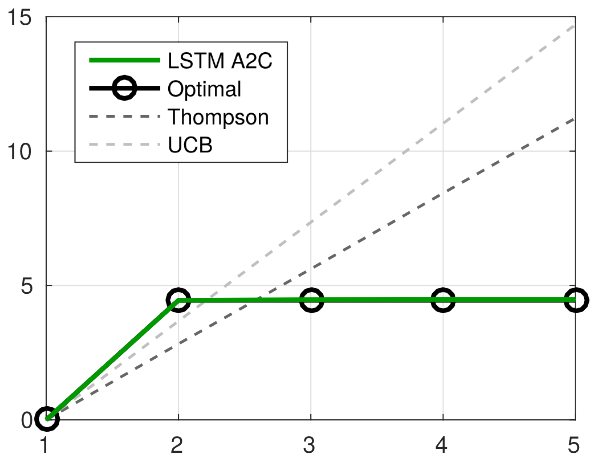
Jane X Wang, Zeb Kurth-Nelson, Dhruva Tirumala, Hubert Soyer, Joel Z Leibo, Remi Munos, Charles Blundell, Dharshan Kumaran, Matt Botvinick
In recent years deep reinforcement learning (RL) systems have attained superhuman performance in a number of challenging task domains. However, a major limitation of such applications is their demand for massive amounts of training data. A critical present objective is thus to develop deep RL methods that can adapt rapidly to new tasks. In the present work we introduce a novel approach to this challenge, which we refer to as deep meta-reinforcement learning. Previous work has shown that recurrent networks can support meta-learning in a fully supervised context. We extend this approach to the RL setting. What emerges is a system that is trained using one RL algorithm, but whose recurrent dynamics implement a second, quite separate RL procedure. This second, learned RL algorithm can differ from the original one in arbitrary ways. Importantly, because it is learned, it is configured to exploit structure in the training domain. We unpack these points in a series of seven proof-of-concept experiments, each of which examines a key aspect of deep meta-RL. We consider prospects for extending and scaling up the approach, and also point out some potentially important implications for neuroscience.
2015
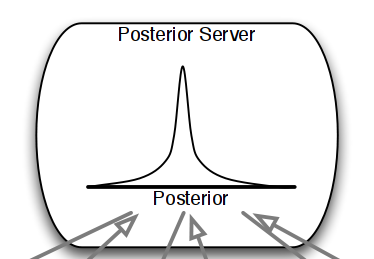
Yee Whye Teh, Leonard Hasenclever, Thibaut Lienart, Sebastian Vollmer, Stefan Webb, Balaji Lakshminarayanan, Charles Blundell
This paper makes two contributions to Bayesian machine learning algorithms. Firstly, we propose stochastic natural gradient expectation propagation (SNEP), a novel alternative to expectation propagation (EP), a popular variational inference algorithm. SNEP is a black box variational algorithm, in that it does not require any simplifying assumptions on the distribution of interest, beyond the existence of some Monte Carlo sampler for estimating the moments of the EP tilted distributions. Further, as opposed to EP which has no guarantee of convergence, SNEP can be shown to be convergent, even when using Monte Carlo moment estimates. Secondly, we propose a novel architecture for distributed Bayesian learning which we call the posterior server. The posterior server allows scalable and robust Bayesian learning in cases where a dataset is stored in a distributed manner across a cluster, with each compute node containing a disjoint subset of data. An independent Monte Carlo sampler is run on each compute node, with direct access only to the local data subset, but which targets an approximation to the global posterior distribution given all data across the whole cluster. This is achieved by using a distributed asynchronous implementation of SNEP to pass messages across the cluster. We demonstrate SNEP and the posterior server on distributed Bayesian learning of logistic regression and neural networks. Keywords: Distributed Learning, Large Scale Learning, Deep Learning, Bayesian Learning, Variational Inference, Expectation Propagation, Stochastic Approximation, Natural Gradient, Markov chain Monte Carlo, Parameter Server, Posterior Server.
Charles Blundell, Julien Cornebise, Koray Kavukcuoglu, Daan Wierstra
We introduce a new, efficient, principled and backpropagation-compatible algorithm for learning a probability distribution on the weights of a neural network, called Bayes by Backprop. It regularises the weights by minimising a compression cost, known as the variational free energy or the expected lower bound on the marginal likelihood. We show that this principled kind of regularisation yields comparable performance to dropout on MNIST classification. We then demonstrate how the learnt uncertainty in the weights can be used to improve generalisation in non-linear regression problems, and how this weight uncertainty can be used to drive the exploration-exploitation trade-off in reinforcement learning.
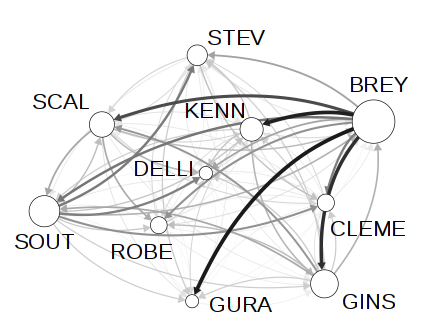
Fangjian Guo, Charles Blundell, Hanna Wallach, Katherine Heller
We present the Bayesian Echo Chamber, a new Bayesian generative model for social interaction data. By modeling the evolution of people's language usage over time, this model discovers latent influence relationships between them. Unlike previous work on inferring influence, which has primarily focused on simple temporal dynamics evidenced via turn-taking behavior, our model captures more nuanced influence relationships, evidenced via linguistic accommodation patterns in interaction content. The model, which is based on a discrete analog of the multivariate Hawkes process, permits a fully Bayesian inference algorithm. We validate our model's ability to discover latent influence patterns using transcripts of arguments heard by the US Supreme Court and the movie "12 Angry Men." We showcase our model's capabilities by using it to infer latent influence patterns from Federal Open Market Committee meeting transcripts, demonstrating state-of-the-art performance at uncovering social dynamics in group discussions.
2014
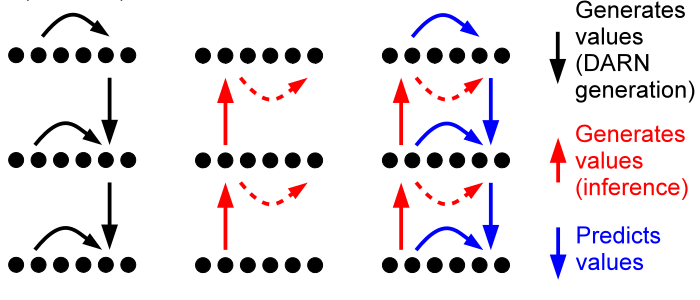
Karol Gregor, Ivo Danihelka, Andriy Mnih, Charles Blundell, Daan Wierstra
We introduce a deep, generative autoencoder capable of learning hierarchies of distributed representations from data. Successive deep stochastic hidden layers are equipped with autoregressive connections, which enable the model to be sampled from quickly and exactly via ancestral sampling. We derive an efficient approximate parameter estimation method based on the minimum description length (MDL) principle, which can be seen as maximising a variational lower bound on the log-likelihood, with a feedforward neural network implementing approximate inference. We demonstrate state-of-the-art generative performance on a number of classic data sets: several UCI data sets, MNIST and Atari 2600 games.
2013
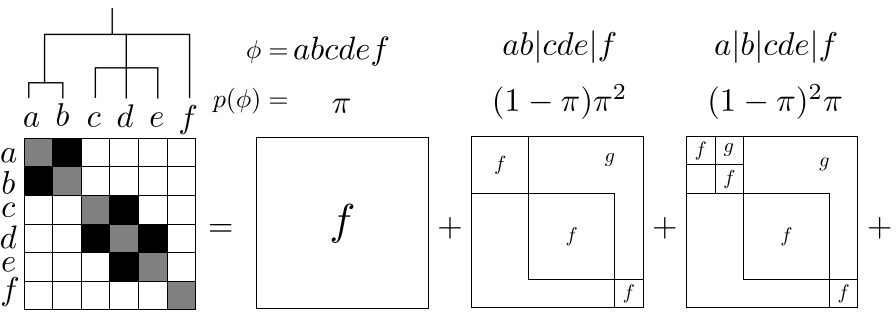
Charles Blundell, Yee Whye Teh
We propose an efficient Bayesian nonparametric model for discovering hierarchical community structure in social networks. Our model is a tree-structured mixture of potentially exponentially many stochastic blockmodels. We describe a family of greedy agglomerative model selection algorithms that take just one pass through the data to learn a fully probabilistic, hierarchical community model. In the worst case, Our algorithms scale quadratically in the number of vertices of the network, but independent of the number of nested communities. In practice, the run time of our algorithms are two orders of magnitude faster than the Infinite Relational Model, achieving comparable or better accuracy.
2012
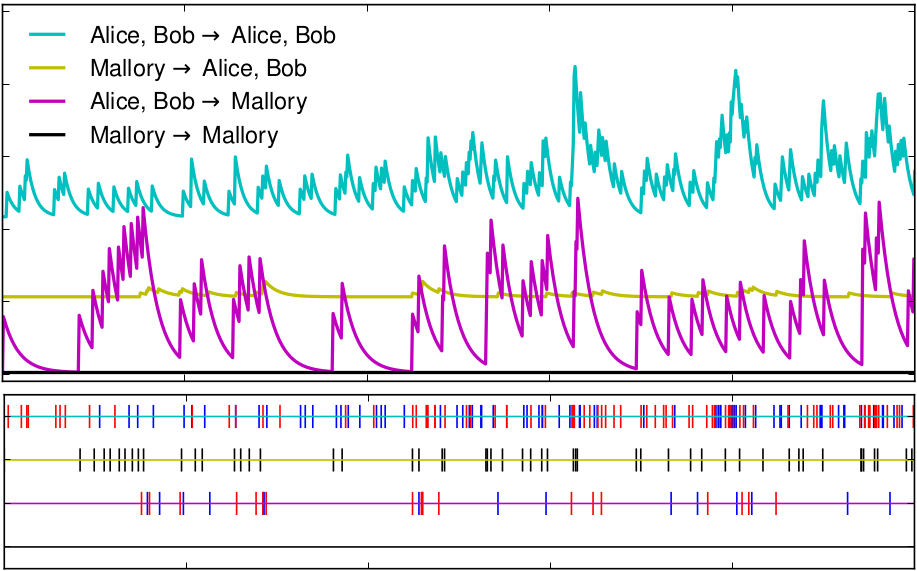
Charles Blundell, Katherine Heller, Jeff Beck
We present a Bayesian nonparametric model that discovers implicit social structure from interaction time-series data. Social groups are often formed implicitly, through actions among members of groups. Yet many models of social networks use explicitly declared relationships to infer social structure. We consider a particular class of Hawkes processes, a doubly stochastic point process, that is able to model reciprocity between groups of individuals. We then extend the Infinite Relational Model by using these reciprocating Hawkes processes to parameterise its edges, making events associated with edges co-dependent through time. Our model outperforms general, unstructured Hawkes processes as well as structured Poisson process-based models at predicting verbal and email turn-taking, and military conflicts among nations.
Charles Blundell, Adam Sanborn, Tom Griffiths
Investigating people's representations of categories of compli- cated objects is a difficult challenge, not least because of the large number of ways in which such objects can vary. To make progress we need to take advantage of the structure of object categories -- one compelling regularity is that object categories can be described by a small number of dimensions. We present Look-Ahead Monte Carlo with People, a method for exploring people's representations of a category where there are many irrelevant dimensions. This method combines ideas from Markov chain Monte Carlo with People, an experimental paradigm derived from an algorithm for sampling complicated distributions, with ideas from hybrid Monte Carlo, a technique that uses directional information to construct efficient statistical sampling algorithms. We show that even in a simple example, our approach takes advantage of the structure of object categories to make experiments shorter and increase our ability to accurately estimate category representations.
2011
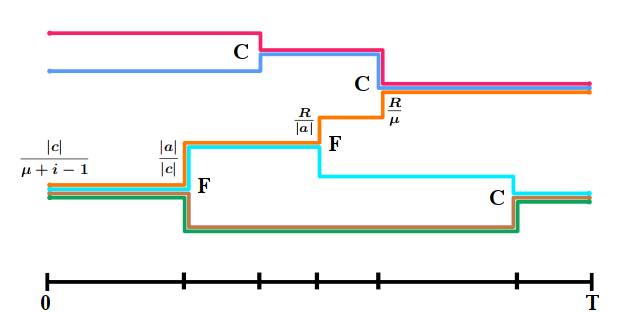
Yee Whye Teh, Charles Blundell, Lloyd T. Elliott
We propose a novel class of Bayesian nonparametric models for sequential data called fragmentation-coagulation processes (FCPs). FCPs model a set of sequences using a partition-valued Markov process which evolves by splitting and merging clusters. An FCP is exchangeable, projective, stationary and reversible, and its equilibrium distributions are given by the Chinese restaurant process. As opposed to hidden Markov models, FCPs allow for flexible modelling of the number of clusters, and they avoid label switching non-identifiability problems. We develop an efficient Gibbs sampler for FCPs which uses uniformization and the forward-backward algorithm. Our development of FCPs is motivated by applications in population genetics, and we demonstrate the utility of FCPs on problems of genotype imputation with phased and unphased SNP data.
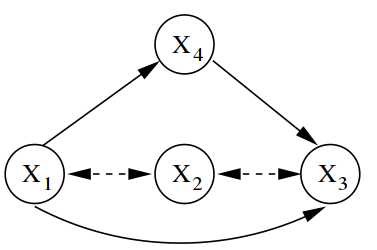
Ricardo Silva, Charles Blundell, Yee Whye Teh
Directed acyclic graphs (DAGs) are a popular framework to express multivariate probability distributions. Acyclic directed mixed graphs (ADMGs) are generalizations of DAGs that can succinctly capture much richer sets of conditional independencies, and are especially useful in modeling the effects of latent variables implicitly. Unfortunately there are currently no good parameterizations of general ADMGs. In this paper, we apply recent work on cumulative distribution networks and copulas to propose one one general construction for ADMG models. We consider a simple parameter estimation approach, and report some encouraging experimental results.
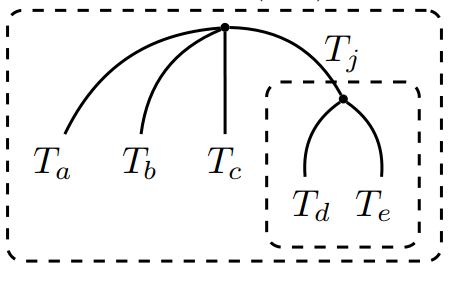
Charles Blundell, Yee Whye Teh, Katherine Heller
Mixtures: Estimation and Applications (2011)
Hierarchical structure is ubiquitous in data across many domains. There are many hierarchical clustering methods, frequently used by domain experts, which strive to discover this structure. However, most of these methods limit discoverable hierarchies to those with binary branching structure. This limitation, while computationally convenient, is often undesirable. In this paper we explore a Bayesian hierarchical clustering algorithm that can produce trees with arbitrary branching structure at each node, known as rose trees. We interpret these trees as mixtures over partitions of a data set, and use a computationally efficient, greedy agglomerative algorithm to find the rose trees which have high marginal likelihood given the data. Lastly, we perform experiments which demonstrate that rose trees are better models of data than the typical binary trees returned by other hierarchical clustering algorithms.
2010
Charles Blundell, Yee Whye Teh, Katherine Heller
Hierarchical structure is ubiquitous in data across many domains. There are many hierarchical clustering methods, frequently used by domain experts, which strive to discover this structure. However, most of these methods limit discoverable hierarchies to those with binary branching structure. This limitation, while computationally convenient, is often undesirable. In this paper we explore a Bayesian hierarchical clustering algorithm that can produce trees with arbitrary branching structure at each node, known as rose trees. We interpret these trees as mixtures over partitions of a data set, and use a computationally efficient, greedy agglomerative algorithm to find the rose trees which have high marginal likelihood given the data. Lastly, we perform experiments which demonstrate that rose trees are better models of data than the typical binary trees returned by other hierarchical clustering algorithms.